Transformers are the foundation of modern NLP models, and for this project, I developed a GPT-style model from the ground up. My implementation included a Transformer Encoder for classifying political speeches and a Transformer Decoder for generating text in an autoregressive manner, following the same structure used in GPT models.
Building the Transformer from Scratch
- Self-Attention Mechanism
- Added multi-head self-attention to allow tokens to reference other words in the sequence.
- Layer Normalization and Residual Connections
- Helped maintain stable training and smooth gradient flow.
- Positional Encodings
- Experimented with AliBi (Attention with Linear Biases) to improve handling of longer sequences.
- Masked Self-Attention
- Used in the decoder so that each token only processed previous words.
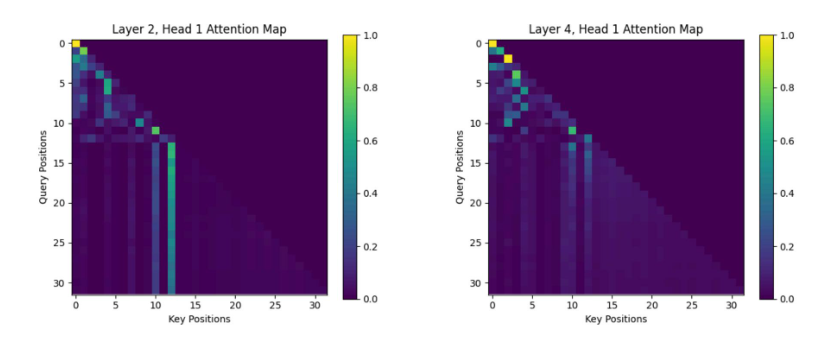 Attention maps from my GPT-style transformer, showing how Layer 2 (left) and Layer 4 (right) distribute attention across different token positions. The diagonal pattern reflects causal self-attention, where each token can only attend to previous tokens, ensuring proper autoregressive text generation. Brighter areas indicate stronger attention weights, highlighting how the model prioritizes key words during processing.
Attention maps from my GPT-style transformer, showing how Layer 2 (left) and Layer 4 (right) distribute attention across different token positions. The diagonal pattern reflects causal self-attention, where each token can only attend to previous tokens, ensuring proper autoregressive text generation. Brighter areas indicate stronger attention weights, highlighting how the model prioritizes key words during processing.
Training a GPT-Style Model
Encoder for Speech Classification
I trained the encoder to predict which politician (Obama, G.W. Bush, or G.H.W. Bush) delivered a given speech segment. This involved:
- Passing tokenized input through self-attention layers to capture speech patterns.
- Using mean pooling to condense the output into a fixed-length representation.
- Training a feedforward classifier to distinguish between speakers.
By the end, the model accurately identified the speaker based on their writing style.
Decoder for Autoregressive Text Generation
To generate text in a GPT-like manner, I built a Transformer Decoder and trained it to predict the next word in a sequence:
- Masked self-attention prevented words from seeing future tokens.
- Custom training loops let the model predict political speeches one word at a time.
- The model picked up on different politicians’ speech patterns, producing text that matched their writing style.
Key Takeaways
This project gave me hands-on experience in building a GPT-like model from scratch, covering:
- How transformers process text using self-attention.
- How autoregressive language modeling works for text generation.
- The effect of different positional encoding strategies on performance.
Writing everything from scratch helped me understand how GPT models function beyond just using existing libraries.