I set up a three-node etcd cluster on AWS EC2 to gain first-hand experience with distributed consensus, leader election, and fault tolerance. The project involved launching virtual machines, configuring firewall rules, installing etcd, and experimenting with cluster behavior under simulated failure conditions.
Visualizing RAFT Consensus
To better understand how RAFT consensus underpins etcd, I used the RAFT simulator.
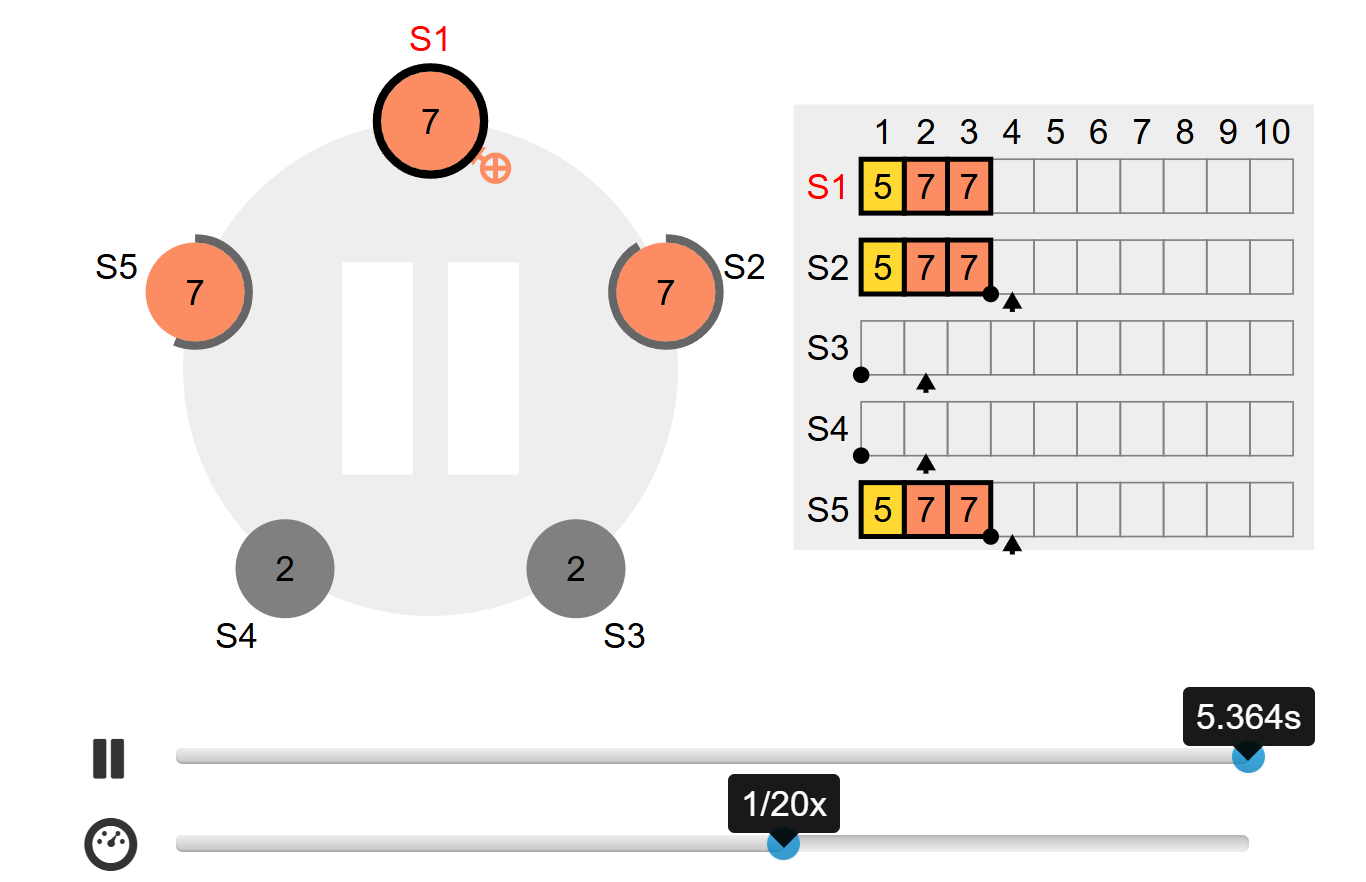
Visualization of RAFT showing a leader failing and a follower being promoted. The simulator was an invaluable tool to understand leader election, log replication, and term changes during failures.
This tool provided an intuitive way to see how:
- One node is elected leader in normal operation
- Followers replicate log entries from the leader
- When the leader fails, a follower is promoted through a new election
- RAFT terms increase each time a new leader is chosen
Setting Up the Cluster
I launched three Debian-based EC2 instances, noted their private IPv4 addresses, and configured a shared security group with inbound rules for ports 2379 and 2380.
On each instance, I installed etcd v3.5.21 and set up environment variables (setupenv.sh) with node names, IP addresses, and cluster tokens. Using these variables, I started etcd on each VM and verified that the three nodes successfully formed a cluster.
Interacting with the Cluster
I used etcdctl to:
- List cluster members and verify connectivity
- Store and retrieve key/value pairs (e.g., writing and retrieving
mypid) - Inspect cluster health with the
endpoint statuscommand
Initially, Node 1 was elected as the leader.
Simulating Failure
To observe RAFT consensus in action, I stopped the EC2 instance running the leader node. Using etcdctl, I confirmed that one of the follower nodes (Node 2 in my experiment) was promoted to leader, and the RAFT term incremented.
Key/value pairs written earlier remained accessible, demonstrating etcd’s fault-tolerant storage guarantees. Once the stopped instance was restarted and etcd relaunched, it rejoined the cluster as a follower.
Takeaways
This project gave me practical experience with:
- Deploying distributed systems on AWS EC2
- Configuring networking and firewall rules for inter-node communication
- Setting up and operating a three-node etcd cluster
- Observing RAFT consensus, leader election, and log replication in a live system
- Verifying fault tolerance by simulating leader node failures and confirming cluster recovery
The RAFT simulator was especially useful in helping me understand consensus theory and complemented the practical work of running etcd in a real cluster.